Durante semanas, el feedback que recibíamos era siempre el mismo:
“Todo va lento.”
“Hay demasiadas incidencias.”
“El delivery no es instantáneo.”
Customer Support estaba saturado de tickets. El CEO tenía la sensación de que algo importante no estaba bajo control. Y desde ingeniería, la realidad era incómoda: no teníamos métricas operativas fiables que nos permitieran discutir nada con datos.
Solo había sensaciones.
Y cuando un sistema complejo se gobierna por sensaciones, pasan dos cosas:
- todo parece urgente,
- nadie sabe realmente si las cosas mejoran o empeoran.
El impulso natural (y equivocado): entenderlo todo
Mi primer impulso fue el clásico: mapear el legacy, entender todos los flujos, identificar la causa raíz del problema del delivery.
En un sistema de e-commerce con:
- pagos asíncronos,
- KYC / antifraude,
- vendors externos,
- reintentos,
- y años de deuda técnica,
ese enfoque no solo es lento: es inviable como estrategia de estabilización.
No porque no sea deseable, sino porque:
- te absorbe cognitivamente,
- te convierte en cuello de botella,
- y no genera impacto visible a corto plazo.
Así que dimos un paso atrás.
Paso 1: definir qué estamos midiendo (antes de medir)
Antes de hablar de métricas, hubo que acordar una definición técnica clara y no discutible.
Time to deliver se definió como:
“el tiempo transcurrido entre que un pedido se crea (
created_at) y el sistema lo marca como completamente procesado (finished_processing_date).”
Sin UX.
Sin percepciones.
Sin marketing.
Un hecho técnico, observable desde base de datos y reproducible con SQL.
Esto es clave: si no defines explícitamente qué estás midiendo, cada conversación futura se convierte en una discusión semántica.
Paso 2: aceptar que la media no sirve
La primera tentación fue sacar una media de tiempos de delivery.
Duró poco.
En cuanto hay:
- pedidos reintentados,
- re-procesamientos,
- órdenes re-marcadas como fulfilled días después,
la media deja de representar nada útil.
Un par de outliers pueden destrozarla por completo.
Así que descartamos la media como métrica principal desde el principio.
Paso 3: elegir métricas que respondan a preguntas reales
No queríamos “muchas métricas”. Queríamos las mínimas necesarias para gobernar el sistema.
Acabamos con tres.
Instant Delivery Rate (≤ 1 minuto)
El claim de marketing era algo como “tu pedido en 5 segundos”.
Desde un punto de vista técnico, 1 minuto ya es extremadamente agresivo:
- pagos,
- validaciones,
- comunicación con vendors,
- workers asíncronos.
Esta métrica no la definimos como SLA ni como objetivo de negocio. La usamos como señal de ingeniería.
La pregunta que responde es muy concreta:
“¿Qué porcentaje de pedidos sigue el happy path sin fricción?”
Cuando empezamos a medirlo, el valor era prácticamente 0%.
Tras varios fixes de estabilización (guardrails, eliminación de loops, mejor manejo de estados), empezamos a ver días con IDR > 30%.
Ese salto fue clave: no porque el número fuera “bueno”, sino porque demostraba impacto directo de los cambios.
Mediana (p50): el pedido típico
La mediana responde a algo mucho más honesto que la media:
“¿Cómo se comporta el pedido normal?”
En nuestro caso, la mayoría de días la mediana estaba en torno a 3–4 minutos.
Esto fue un cambio de narrativa enorme.
El sistema no era “lento” en general. Era razonablemente rápido para la mayoría, pero con problemas graves en ciertos casos.
p95: la cola de riesgo
El p95 nos enseñó la parte incómoda:
- pedidos que tardaban decenas de minutos,
- otros que tardaban horas en días de incidente.
Ahí viven:
- refunds,
- PayPal / Klarna cases,
- tickets de soporte.
El p95 no es una métrica para optimizar directamente. Es una métrica para detectar y reducir riesgo.
Paso 4: SQL simple, sin infraestructura nueva
Todo esto se sacó con una query SQL relativamente fea, usando:
- window functions,
- ranking por día,
- y percentiles calculados a mano.
Nada de pipelines. Nada de dashboards automáticos.
Los resultados se pegaban en un Excel / Google Sheets y se actualizaban cada pocos días.
Esto fue intencional:
- cero riesgo para producción,
- cero coste cognitivo adicional,
- feedback rápido.
La sofisticación vendría después (si hacía falta).
Paso 5: visualización mínima, pero honesta
Tres gráficas:
- mediana de time to deliver
- p95 de time to deliver
- instant delivery rate ≤ 1 minuto
Nada más.
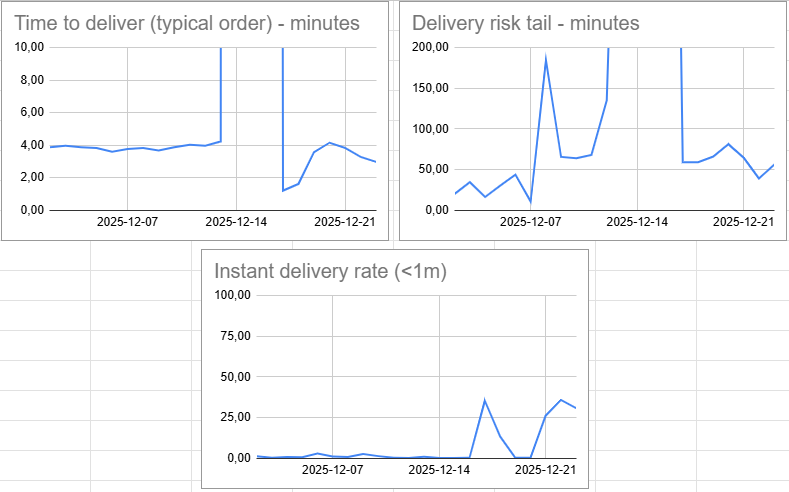
Estas tres juntas cuentan una historia muy clara:
- el pedido típico,
- el dolor real,
- y la limpieza del happy path.
Y lo más importante: no se contradicen entre sí.
El impacto real (más allá de los números)
Estas métricas no solo sirvieron para “analizar”.
Sirvieron para:
- darle al CEO visibilidad real del estado del sistema,
- alinear a Customer Support con datos, no con intuiciones,
- priorizar trabajo de estabilización con criterio,
- y, sinceramente, bajar el nivel de ansiedad del equipo técnico.
Cuando puedes decir: “el pedido típico tarda X, el riesgo está aquí, y esto está mejorando”, el caos deja de gobernarte.
Lo que NO hicimos a propósito
- No intentamos explicar cada outlier
- No prometimos SLAs irreales
- No optimizamos para el p95 a cualquier coste
- No automatizamos métricas prematuramente
Primero visibilidad. Luego control. Después optimización.
La lección que me llevo
En sistemas legacy, liderar ingeniería no va de salvarlo todo.
Va de:
- elegir bien qué medir,
- hacer visible el progreso,
- reducir riesgo de forma incremental,
- y crear confianza mientras tanto.
Las métricas no arreglan el sistema. Pero sin ellas, el sistema te arrastra.
Y eso, tarde o temprano, se paga.
Te dejo la pregunta para cerrar:
¿Qué métricas te han permitido a ti pasar del “todo va mal” a decisiones técnicas con calma y criterio en sistemas reales?
